从LeNet到DenseNet:Transformer前卷积神经网络的一些优化技巧/结构优化
本文从LeNet开始,通过AlexNet,VGG,GoogLeNet,ResNet,Inception v2-4, DenseNet这些Transformer注意力时代前的热门CNN模型,总结出一些优化技巧和结构,分析为什么这些优化成功的提升了模型的表达能力/泛化能力/优化能力。
热门获奖模型的细节演变
从一个角度来看,模型演变基本上是在提升三个能力:
- 提升表达能力(Representation ability)可以让模型(更好的)拟合复杂的函数,或者说,从数据中学习到有效特征。
- 提升优化能力(Optimization ability)可以让模型更加容易快速的找到参数(近似)解,模型梯度过大/过小,参数过多都会导致模型训练(寻找解)便慢。
- 提升泛化能力(Generalization ability)就是在提升模型对于新数据的准确率,准确来说,是让模型抛弃一些细枝末节的噪声/细节,去关注更本质的规律。
LeNet-5 (1998)
http://yann.lecun.com/exdb/publis/pdf/lecun-01a.pdf
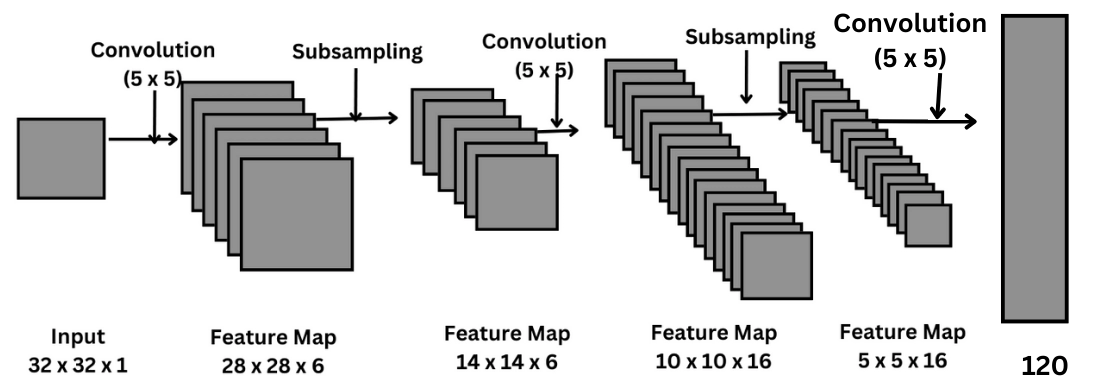
模型可以用C1 S2 C3 S4 C5 F6来进行简化描述,其中C代表的是convolution卷积层,S代表的是Subsampling/pooling池化操作,F代表的是FC(Fully Connected)全连接层。
卷积层
LeCun开创性的使用了卷积层和卷积核的概念来尝试提取每个5x5小图的局部信息。这里的卷积核全部是5x5大小的。
和传统的神经网络相比,LeNet可以更好的分理出局部信息,把相邻像素看作是一个整体,增加了模型输入时获取到的信息量,可以更好地进行抽象化,分离,分类。
并且通过使用多层卷积层,可以提取出越来越抽象的信息,比如从最开始的提取边缘,纹理,到后面的提取某个抽象意义上的整体。
C1层通过同时训练6组卷积核参数组成6个通道来同时提取局部不同的特征和信息。这里每组卷积核参数都会作用在输入的所有通道,某种意义上进行了参数/权重共享的操作,降低了模型的参数量。
C3层的16个通道并不是全部都连接了S2输入的6个通道,通过类似于后面dropout的方法进行剪枝,减少了计算量。
池化层
池化层显著的降低了输入的维度,去噪。
LeNet使用了平均池化而不是最大池化,在后面我们可以看到为什么现在的CNN模型都是用最大池化。
全连接层
这里使用的是欧氏距离径向基函数RBF(基于距离)而不是现在常用的Softmax。
AlexNet (2012)
https://proceedings.neurips.cc/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf
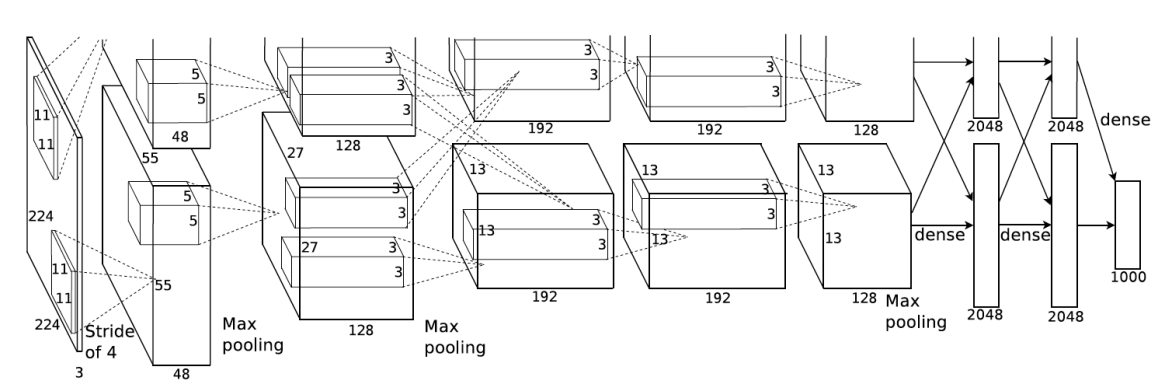
可以看到AlexNet使用了不同大小的卷积核11x11, 5x5, 3x3来模拟逐渐抽象这一过程。
更深的网络结构
AlexNet通过增加卷积层/池化层/全连接层数量来扩展了模型的抽象能力,从之前的简单数字提取到现在的复杂图像识别。
激活函数ReLU
LeNet之前用的Sigmoid / tanh激活函数在深层网络中很容易引发梯度消失问题,并且在计算上也有些复杂,这两者导致模型训练比较困难,AlexNet则应用了ReLU激活函数,不仅解决了这两个问题,提高了模型的优化能力,还增加了模型的稀疏性 - 部分神经元输出为0,提高了模型的泛化能力。
数据增强(Data Augmentation)
AlexNet通过对训练图像进行随机裁剪、水平翻转、亮度和对比度调整等操作,极大地扩充了训练数据集,让模型学习到对各种变化的鲁棒性(robustness),这对应了模型的泛化能力。
Dropout
AlexNet在训练过程中,以一定的概率随机地“丢弃”一部分神经元,即不参与前向和后向传播。
最大池化
相比平均池化,最大池化更能保留,捕捉和提取特征,还能减少噪音/无关信息干扰。
VGG-16 (2014)
https://arxiv.org/pdf/1409.1556.pdf
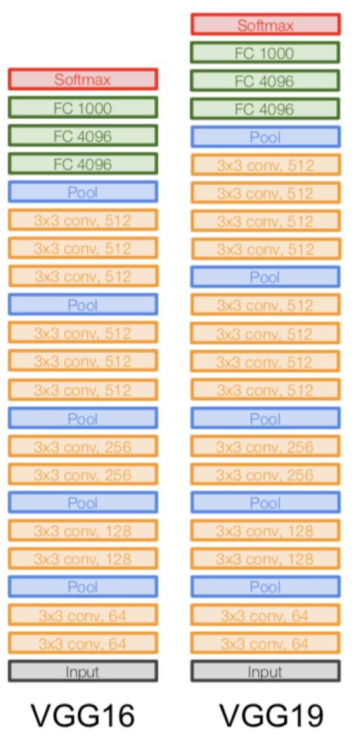
在AlexNet的基础上,VGG显著的增加了层数。
VGG的基本构建单元是一个“模块”,由2到3个连续的3x3卷积层(步长为1,填充为1)组成,之后紧跟一个2x2的最大池化层(步长为2)15。
更小的卷积核
VGG只用了3x3的卷积核,三层3x3的卷积核等效一层7x7的,但是因为有三层,增加了模型的深度和非线性。参数量也从\(7^2C^2\)减少\(3\times(3^2C^2)\) 。
尽管如此,因为模型的深度,参数量还是显著的增加了。
模块化模型
VGG带来了一种新的模型设计思路。之前的模型卷积层,池化层,卷积核大小设计和分配都较为随意,或者说随心。而VGG重复的使用了卷积堆叠+池化的模块来增加模型深度。
GoogLeNet / Inception v1 (2014)
https://arxiv.org/pdf/1409.4842.pdf
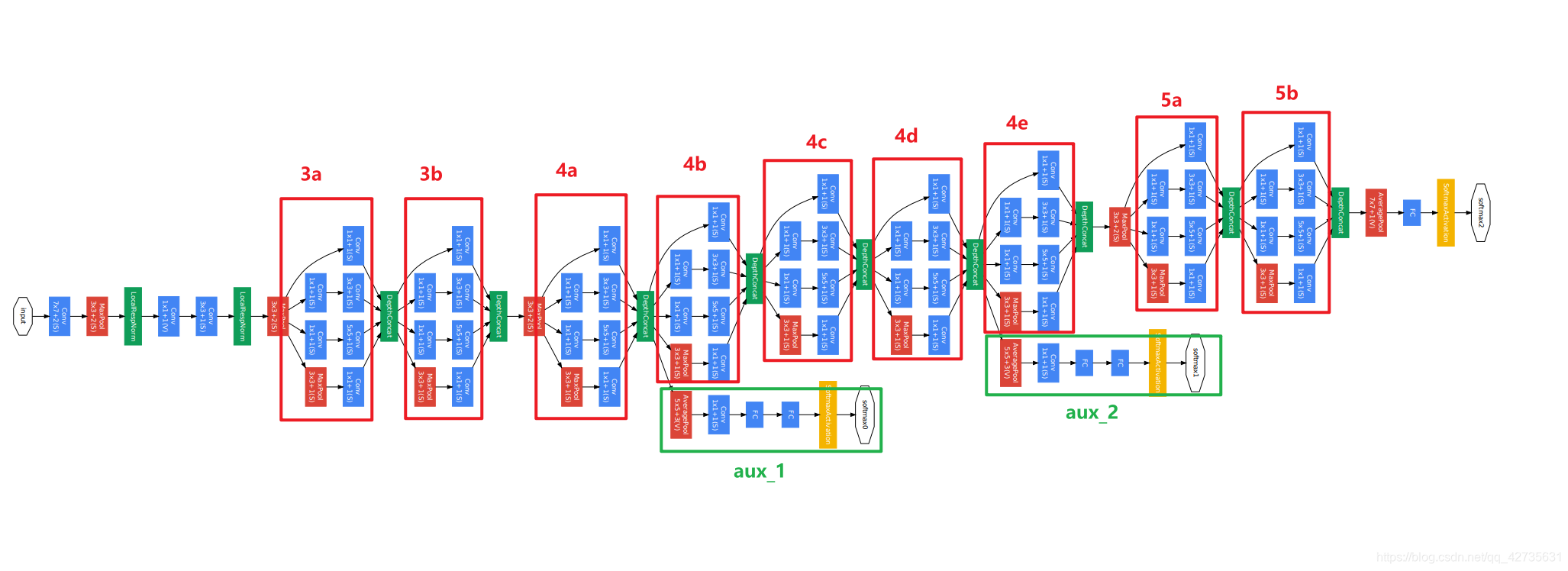
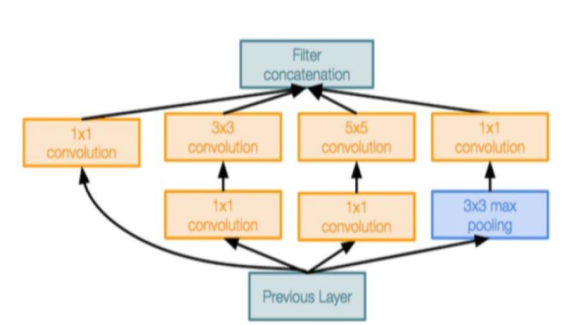
可以看到GoogLeNet通过重复堆叠名为Inception的模块来一步步的抽象化输入。输入也不仅仅考虑最深层模型的结果,还结合两个在更浅层的辅助输出模块。
Inception模块
GoogLeNet的核心洞察就是图像中物体的尺寸差异巨大,因此在同一层级上进行多尺度特征提取是有益的 。
基于这个设计理念,Inception模块在同层内并行执行多种操作:1x1 3x3 5x5卷积,以及3x3最大池化。最后将四者的输出用不同通道的方式整合起来。
这种并行结构允许网络在同一层级同时捕捉不同尺度的特征,从而极大地增强了网络的表达能力。其理论基础是,这种密集的并行结构可以有效地近似一个最优的、但难以构建的稀疏网络拓扑。
1x1瓶颈卷积层
可以注意到如果模块单纯做并行运算,那么每层的输出通道数量将会变得十分庞大,为此,GoogLeNet引入了1x1卷积来减少输入的通道数。
辅助分类器
正如前面所说的,为了解决极深网络中普遍存在的梯度消失问题,GoogLeNet在网络中间层引入了两个辅助分类器。
在非常深的网络中,梯度从输出层反向传播到浅层网络时可能会变得非常小,导致浅层网络的权重更新缓慢甚至停滞。
GoogLeNet在网络的中间层增加了两个辅助的分类器。在训练阶段,这两个辅助分类器的损失会以一个较小的权重(0.3)被加到网络的总损失中。
这种设计相当于在网络的中间部分“注入”了额外的梯度信号,确保了即使是较浅的层也能接收到有效的监督信息,从而学习到有用的特征。这不仅有助于缓解梯度消失,加速收敛,也起到了一定的正则化作用。
Inception v2 (2015)
V2基于两篇论文对V1做出了改进:
批量归一化(Batch Normalization, BN)
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
在训练过程中,由于前面各层参数的不断更新,导致每一层输入的数据分布也在持续变化,这种变化被称为内部协变量偏移 (Internal Covariate Shift, ICS)。
它迫使网络各层必须不断去适应新的输入分布,这不仅会减慢训练速度,还要求使用更小的学习率和更谨慎的参数初始化。
为了解决这个问题,V2在卷积层与激活函数之间插入了BN层(全连接层和后续非线性激活函数之间也可以插入BN层),具体来说,BN通过在每个mini-batch上对层的输出(激活值)进行归一化,使其恢复到均值为0、方差为1的标准分布。
卷积分解(Factorizing Convolutions)
Rethinking the Inception Architecture for Computer Vision
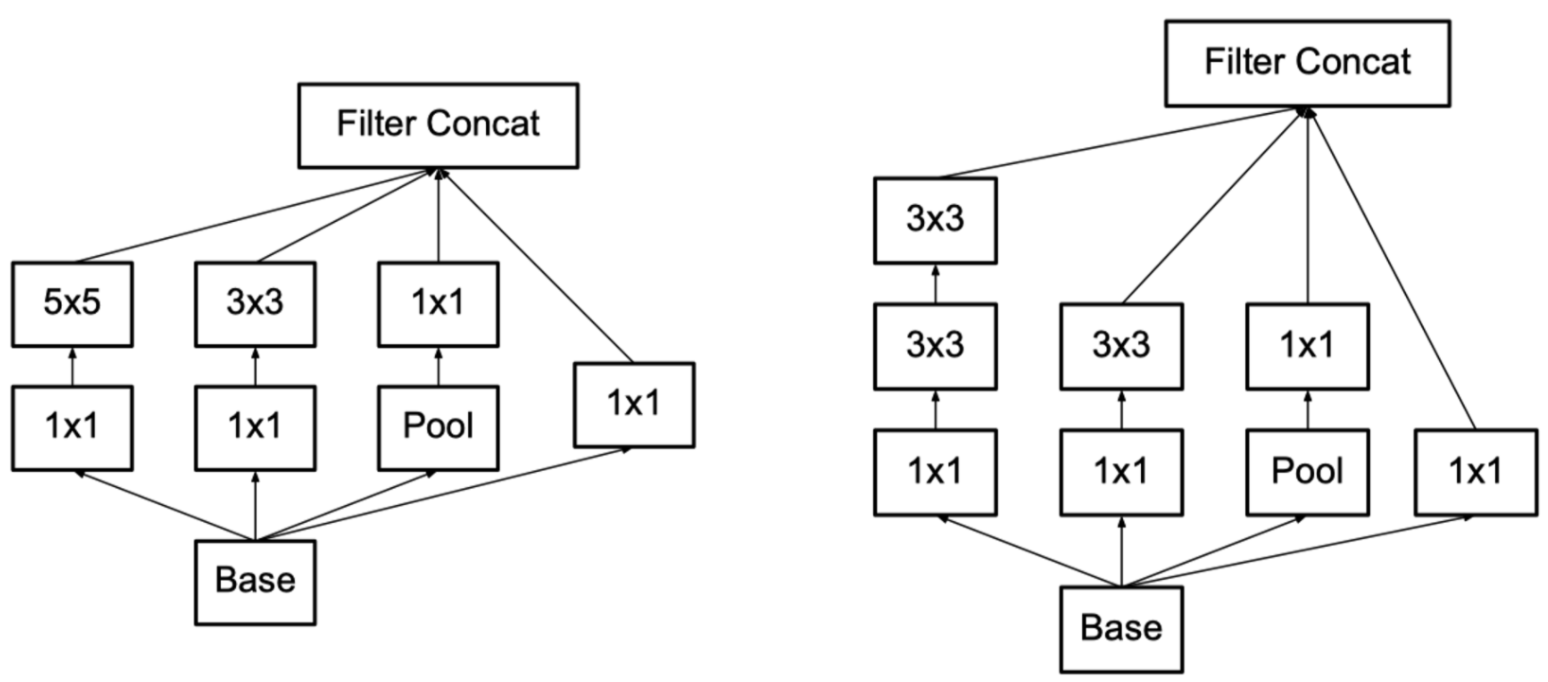
正如前面3x3卷积对于7x7卷积参数量的优化,V2进一步的把5x5分解成了两个3x3卷积层。
Inception v3 (2015)
https://arxiv.org/pdf/1512.00567.pdf
进一步分解卷积
V3作者探讨了两种卷积分解方法,对称卷积分解和非对称卷积分解
对称卷积分解
对应了V2中提到的用小卷积核串联来模拟替代大卷积核。从数据上来看这么做不会影响模型的表达能力,并且减少了模型的参数量。
非对称卷积分解
尝试着将对称卷积分解分解成更小的卷积层
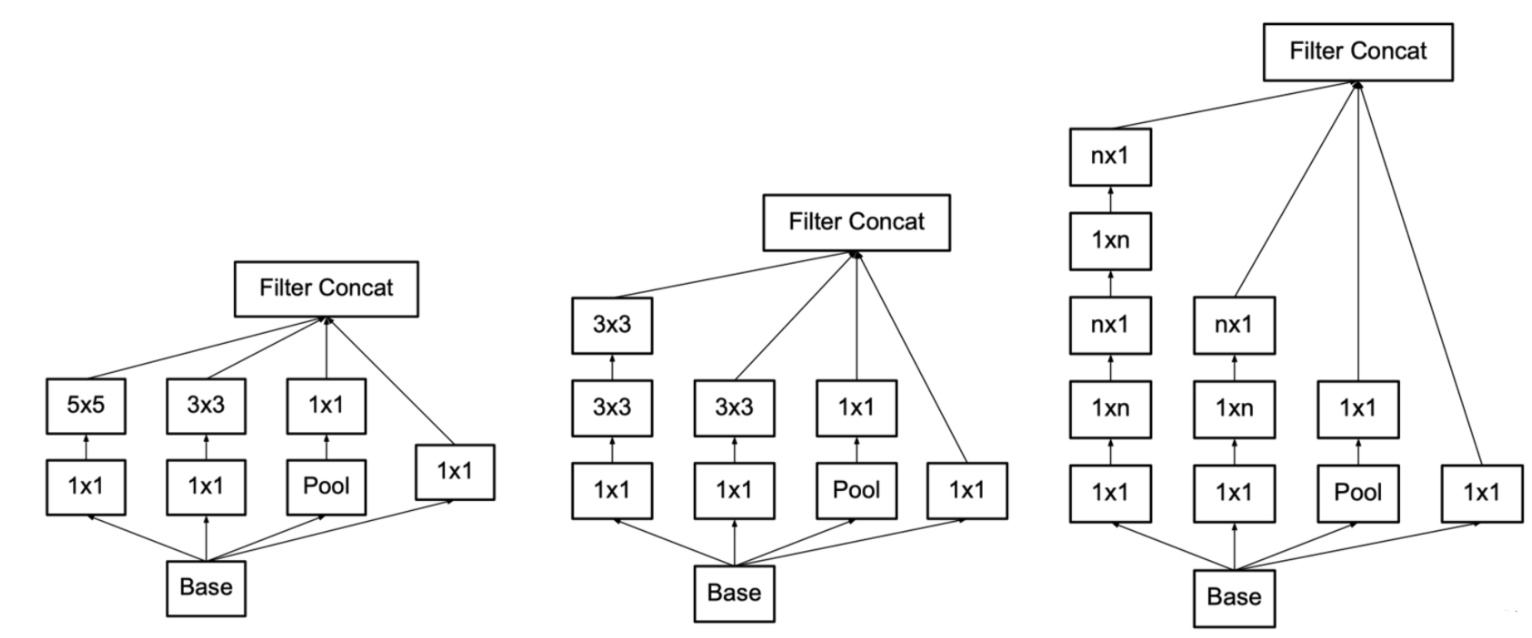
例如,将nxn大小的卷积分解成1xn和nx1卷积的串联。
看起来这么分解大大的减少了参数量,但实际上效果,尤其是在网络浅层是用,效果并不好,feature map大小也最好保持在12到20之间。
ResNet-152 (2015)
https://arxiv.org/pdf/1512.03385.pdf
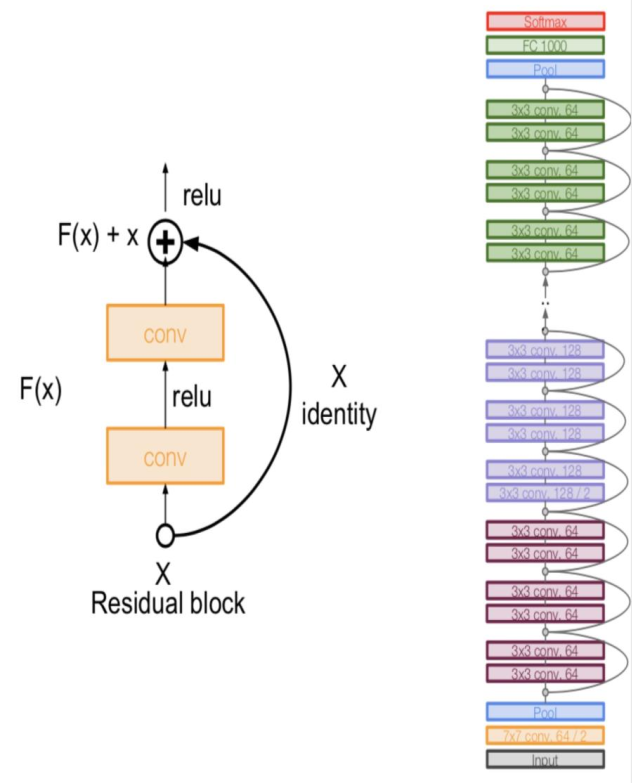
前面的几个模型可以看到都在越做越深,这就造成了一个不可避免的问题:网络退化(更深未必更好)。
残差模块(Residual block)
ResNet通过构造了残差模块Residual block,特别是是上图的identity mapping X,来改变每个模块的学习目标:从直接学习一个期望的底层映射\(H(x)\)到学习一个残差映射\(F(x)=H(x)-x\)。
这样的想法类似于AdaBoost的提升(boosting)。ResNet的每一个残差模块都在学习如何在前一模块的基础上对这一模块进行修正和调整。
类似的,从集成学习的角度来看,ResNet可以看作是多个模块的组合:
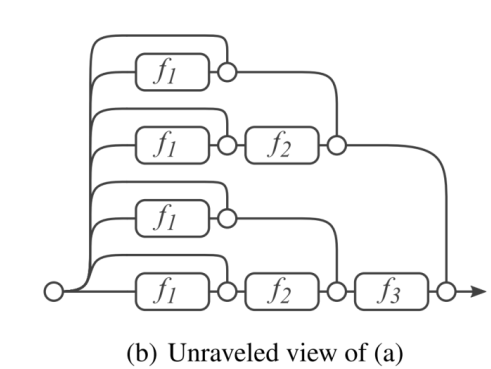
这一重构带来了巨大的优化优势。如果某个网络层的最优函数就是一个恒等映射(\(H(x) = x\)),那么优化器只需将残差函数\(F(x)\)的权重和偏置推向零即可。这远比通过多个复杂的非线性层来拟合一个恒等函数要容易得多。
因为深层模型最大的问题梯度消失解决了,这让使用残差模块的模型可以变得更深了,变相的增加了模型的表达能力。
Inception v4 (2016)
https://arxiv.org/pdf/1602.07261.pdf
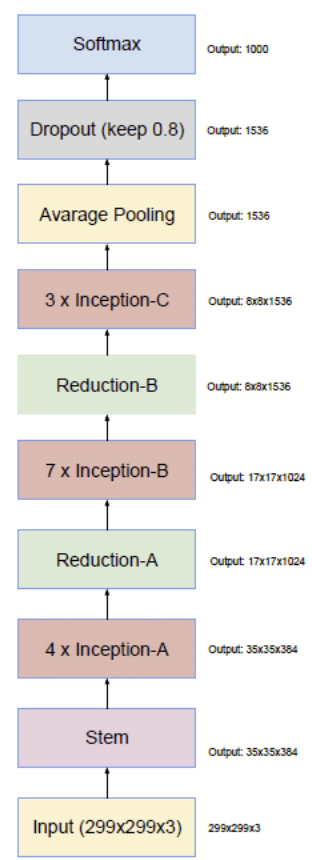
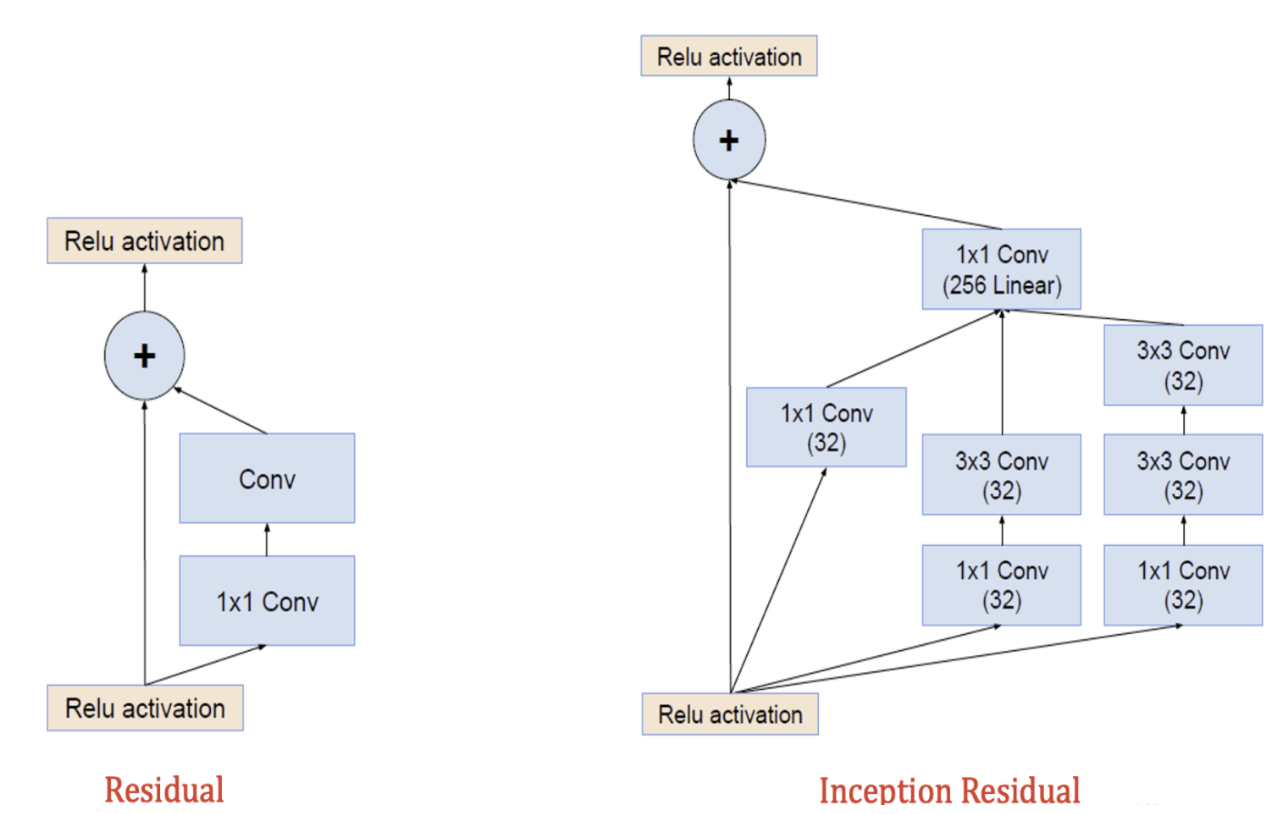
基于ResNet的残差理念,Google进一步结合残差模块和inception模块,创造出了Inception V4和其Inception Residual模块。
DenseNet (2017)
https://arxiv.org/pdf/1608.06993.pdf
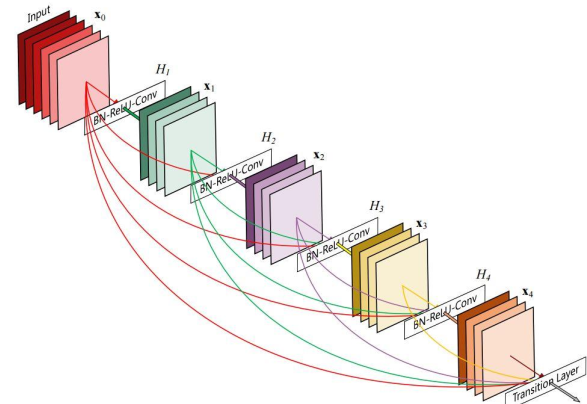
DenseNet将ResNet的残差学习理论推向了极致。ResNet仅仅是让每一模块变成对上一模块的修正和补充,而DenseNet将前面所有模块的输出都直接输入到当前模块(通过通道拼接的方式)。
这样做增加了特征的使用次数,每层只需要学习很少量的新特征图,大大的减少了所需参数量。比如说,第十层现在可以调用第一层提取的边缘和纹理特征。

当然,对于一个特别深的模型来说,将所有模块都连接起来是不理想的,通道数过于庞大了。为了解决这个问题,DenseNet划分网络为多个密集块(Dense Block),块和块之间通过一个过渡层相连,其中包括一个1x1卷积层和池化层来减少通道数。
