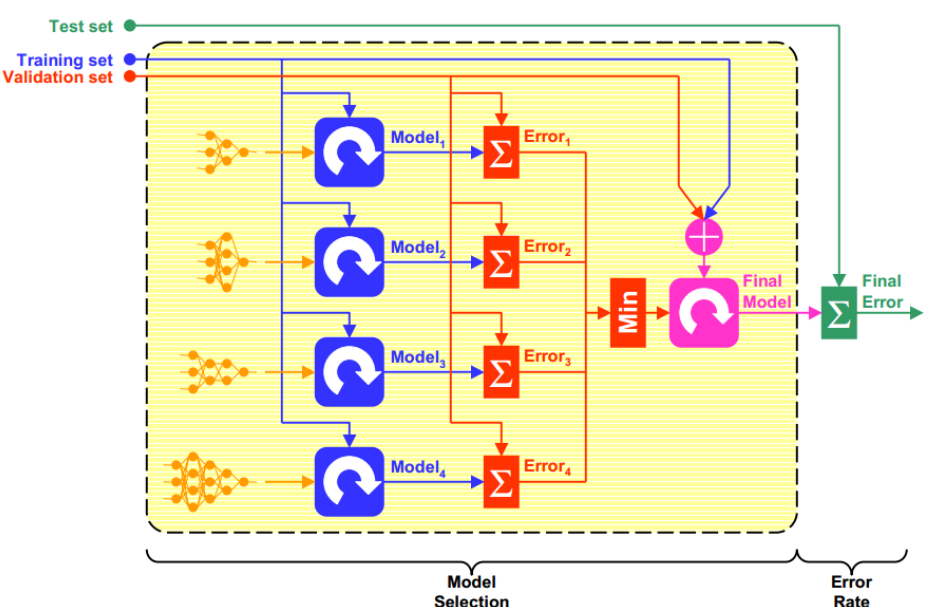
模型验证与评估
如何选择模型超参数与模型评估。
选择模型超参数
所有机器学习模型都有一些超参数:
- k-NN的邻居数量\(k\)
- SVM的核函数
- MLP的结构(每层大小和深度)
- …
如何知道哪个超参数更好,或者哪个模型更好呢?
理论上对于无限均匀数据,直接拟合全部数据,错误率就是模型实际的错误率。
但对于现实的有限数据,尤其是数量不多、不够的情况下,用所有数据去拟合,就没法知道模型对于未见数据的表现能力了(没数据来测试)。
留出法 Holdout Method
简单的将输入分为两个数据集:训练集(training set)和测试集(test set),一般是80%和20%。
- 训练集:用来让模型拟合。
- 测试集:用来评估模型的错误率。

如可以在判断梯度下降模型多少epoch刚刚好不会过拟合也不会欠拟合:
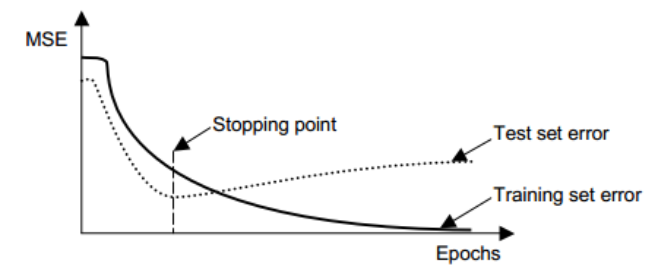
这么做有两个问题。
- 数据本来就不够的情况还要分一部分作为测试集,导致样本数量过少噪音变多拟合不好。
- 单次划分可能并不均匀,有可能划分的十分极端。
重采样 Resampling
为了避免上面的两个问题,可以通过重采样的方法,用更多的计算时间来“平均掉”极端情况。
随机子采样 Random Subsampling
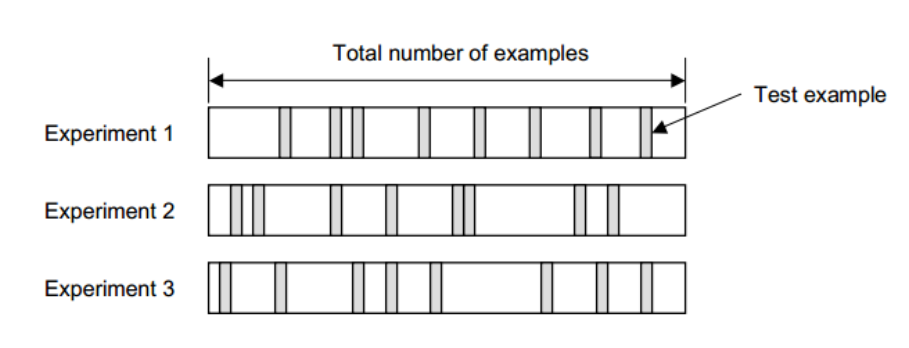
进行\(K\)次随机分割,分别训练\(K\)次,然后用其测试集评估其性能。
最后的错误率就是\(K\)次的平均
\[E=\frac1K\sum_{k=1}^K E_k\]
K-折交叉验证 K-Fold Cross-validation

直接将数据分为\(K\)个折(folds),每次留一个进行训练,然后用留下的进行测试。
相比于随机子采样,所有数据都保证了会用在训练和测试。
错误率和随机子采样一样。
留一法 Leave-one-out Cross-validation
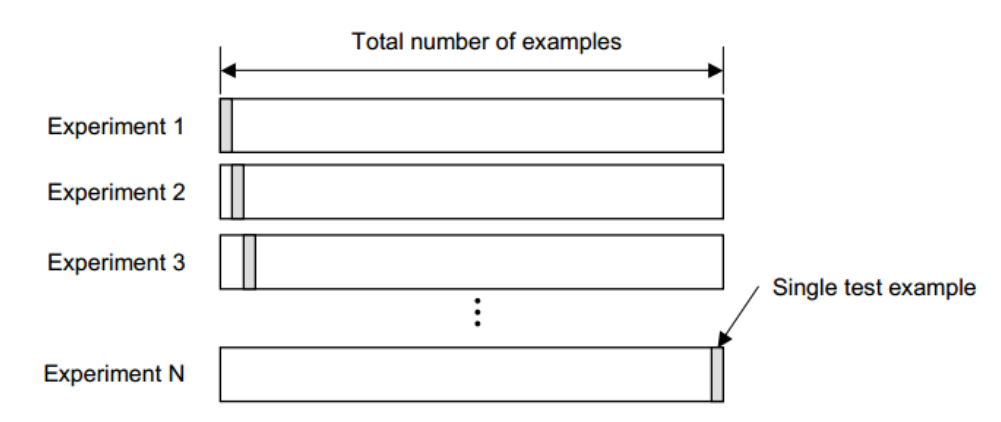
K-折的极端情况,\(K=N\)。
如何选择\(K\)
大的\(K\)导致对于真实误差估计的偏差小(更准确),方差大(训练集区别不大),并且计算量大。
小的\(K\)计算量小,方差也小,但偏差大(取决于学习曲率)
方差和偏差参考此文前面:受AdaBoost启发的Margin Theory间隔理论 - alittlebear’s blog
实践中数据集够大可以选择较小\(K\),数据集小就需要选择大一点的\(K\),一般用\(K=10\)。
模型评估
如果在选择超参数的基础之上我们还需要评价模型性能(也就是模型对于真实错误率的估计情况),那么我们需要将模型分为三个不相交子集:
- 训练集;
- 验证集:上一节的测试集,用于测试并最终用来选择最佳超参数。
- 测试集:用来评估最终模型的性能,也就是这个调参完成的模型在实际新数据表现如何。