机器学习的学习规则
机器学习模型可以通过优化不同目标来达成不同的目的:
- 误差修正学习
- 竞争学习
- 赫布学习
- 玻尔兹曼学习
- 基于记忆的学习
现在主流的深度神经网络(CNN,Transformer)都是基于误差修正学习,最小化损失函数(激活函数和损失函数 - alittlebear’s blog)。
深度学习是如何统治所有机器学习的学习类型的 - alittlebear’s blog 这篇文章可以看到现在的深度学习是如何融合之前这五种学习规则,变为各方面的全能。
机器学习的学习规则
机器学习模型可以通过优化不同目标来达成不同的目的。
误差修正学习(Error-correction learning)
- 深度神经网络(CNN, RNN, Transformer)的反向传播算法(Backpropagation):深度神经网络
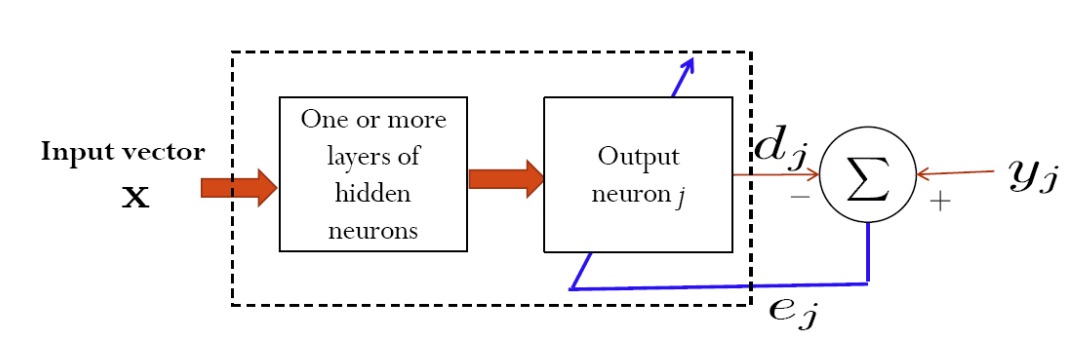
如上图所示,误差修正学习的基本流程就是让模型跑一遍输入,将输出和正确标签(输出)进行比较,然后用误差来调整模型权重、参数,以减少下一次的误差。
这种学习的目标是让模型拟合真实的输出,为此,其最小化损失函数(如分类错误率或均方误差)。
可以看到,下一小节会讨论的深度神经网络的误差反向传播算法就是误差修正学习。线性回归、逻辑回归等广义线性模型也都是通过最小化某种损失来进行拟合,这些都属于误差修正学习。
但,这种学习方式仅限于监督学习(需要输入的真实标签、输出)。
竞争学习(Competitive learning)
- 自组织映射(Self-Organizing Maps,SOM):自组织映射 - 维基百科,自由的百科全书
- K-Means 聚类:聚类,混合模型,和EM算法 - alittlebear’s blog,k-平均演算法 - 维基百科,自由的百科全书
相比于监督学习的误差修正学习,竞争学习作为一种无监督学习方式,主要用于聚类或特征提取。
从名字可以看出来,其核心思想是只对输入反应最强烈的(神经元、邻域;彼此互相抑制)进行更新、学习。
赫布学习(Hebbian learning)
- 联想记忆网络神经网络 (Hopfield Network):霍普菲尔德神经网络 - 维基百科,自由的百科全书
- 主成分分析 (PCA) 的神经网络实现:主成分分析 - 维基百科,自由的百科全书,主成分分析结合长短期神经网络学习算法 主成分分析和神经网络
考虑早期最经典的神经学研究之一:巴甫洛夫的狗。研究发现只要铃声响(神经元A)和给食物(神经元B)同时发生,狗的大脑就会在两者之间建立强连接(通过NMDA受体)。
基于这个学习思路,如果两个连接的目标(神经元)同时被激活,之前的连接权重就会增加。
玻尔兹曼学习(Boltzmann learning)
模拟物理世界统计力学和热力学(关于能量)的方法,将网络视为一个物理系统,通过调整权重,引用随机性和学习阶段 - 正相(positive phase)和负相(negative phase),将网络变为低能量状态。
基于记忆的学习(Memory-based learning)
也叫基于实例的学习(instance-based learning)、懒惰学习(lazy learning)。
这种方法几乎不做任何计算,死记硬背的把所有数据存储起来,需要的时候通过寻找最相似的一个或者多个样本判断输出。
| 学习范式 | 核心机制 | 监督类型 | 典型代表 | 关键词 |
|---|---|---|---|---|
| 误差修正 | 最小化目标与输出的误差 | 有监督 | BP 神经网络, CNN | 梯度下降, 反向传播 |
| 竞争学习 | 神经元争夺响应权 | 无监督 | SOM, 聚类 | 胜者为王, 侧向抑制 |
| 赫布学习 | 突触前后的相关性 | 无监督 | Hopfield 网络 | 同步激活, 生物启发 |
| 波尔兹曼 | 匹配数据分布 (能量最小) | 无监督/生成式 | RBM, DBN | 统计力学, 随机性 |
| 基于记忆 | 存储实例,按相似度检索 | 有监督 (通常) | k-NN | 懒惰学习, 查表 |
